Often times you are required to store large amounts of call data resulting in millions of call rows in a single database. Housing large amounts of call data in a single database can be resource intensive when your day to day reporting requirements are usually only one, two or three months of call data.
Variphy 13.0 introduced the ability to support multiple databases within a singe cluster. Variphy’s Auto Archiving feature provides functionality to automatically create “Archive databases” that house less used call data, freeing up valuable resources for your day to day reporting but leaving the archived data available for seamless reporting when needed.
THIS ARTICLE IS INTENDED FOR VARIPHY CUSTOMERS WHO ARE CONFIGURING AUTO DATABASE ARCHIVING ON A NEW CLUSTER OR A CLUSTER THAT HAS NOT BEEN COLLECTING DATA VERY LONG.
IF YOU HAVE AN EXISTING CLUSTER AND YOU WISH TO CONFIGURE AUTO DATABASE ARCHIVING THIS ARTICLE IS NOT FOR YOU. PLEASE PROCEED TO: How to configure Auto Database Archiving on an existing Cluster.
1. Configuring Auto Database Archiving on a new Cluster.
- Log into the Variphy web interface and navigate to the System Settings gear icon.
- Select the Cluster type that you will be archiving (CUCM, CUBE etc… ).

- Navigate to the CDR Processing tab and edit the cluster you will configuring for Auto Archiving.
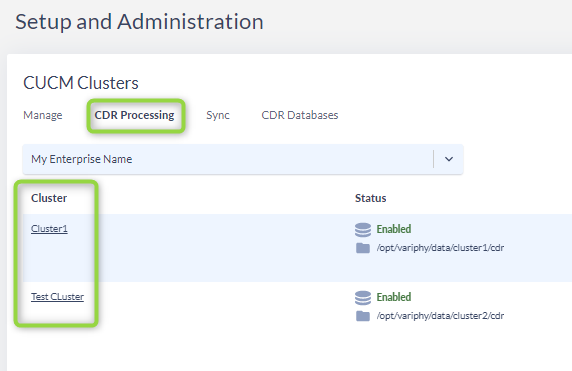
- In the CDR Processing menu navigate to the Database Processing section and toggle on Enable Database Archiving and Enable Auto-Archiving Schedule.
- In the Active Database Archiving section use the Active Archive Database Server drop down to select the database server that you wish your archives to be stored.
- One of the benefits of Auto Archiving is that the archive databases do not need to reside on the same server as your primary database. Keeping your Primary reporting database on one database server while your archives reside on another is recommended to help improve day to day reporting experience.

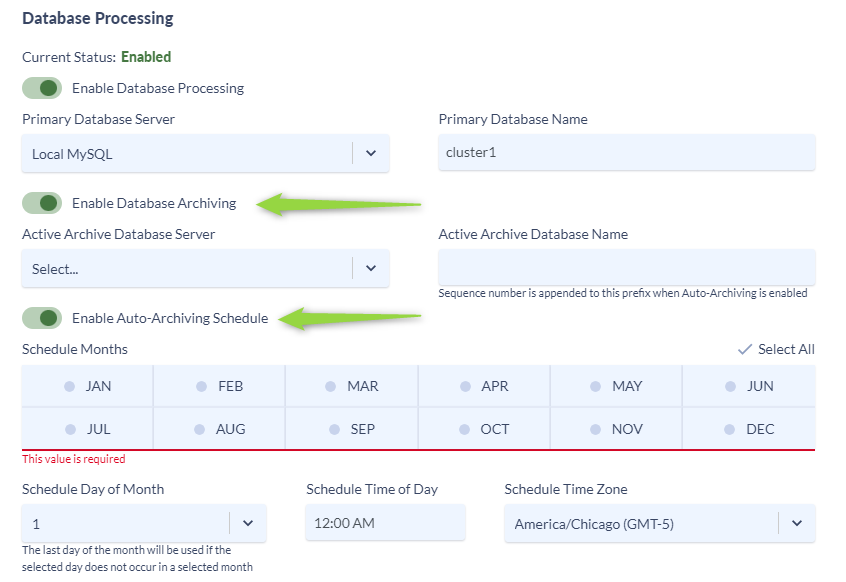
- In the Primary Database Name section give your database a name _primary. For example “cluster1_primary” as seen below. If you already have a name for your Primary database skip this step.
- In the Active Database Archive section give your Active Archive Database a name. For consistency it is recommended to use the same name as your original Primary Database and append “_archive”. Variphy will automatically append a sequence number to the prefix of the archives.
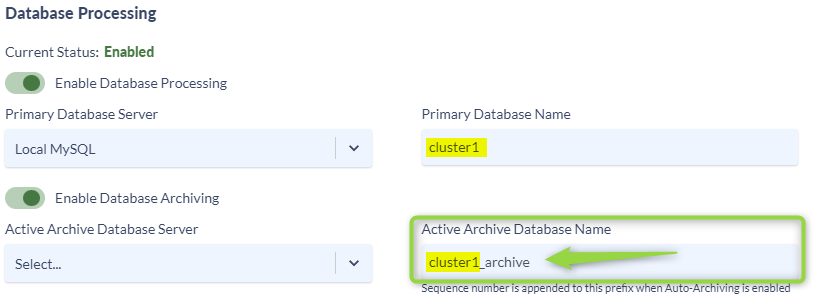
- In the Auto Archiving Schedule section define the schedule you want the auto archiving to run.
- Select the Months you wish the archiving to run.
- Select the day of the month and time the archive will run.
In this example I am Archiving my database every 3 month on the 15th of the month at 4:00 AM. This will result in a new Active Archive database being created every three months housing the previous 3 months of data.
There is no single best Archiving schedule as it varies dependent on your call volume and system usage. If you have a larger volume of calls, say 5+ million a month, and you frequently need to access older data, you may want to run monthly or bi-monthly archives, keeping your archive databases smaller for faster querying. If you have a smaller call volume but require lengthy retention but rarely need to access that older data, you may want to archive quarterly keeping larger archives that are accessed less frequently.
- Scroll down to the Primary Database Purge Settings and adjust your purge schedule.
- The Primary Database Purge schedule will only purge the Primary database keeping all of the archive data intact and available for seamless reporting. The purge schedule of your primary database should reflect your common reporting requirements. For example. If you normally run Daily, Weekly & Monthly reports you would have the primary database only house 1 or 2 months of data.
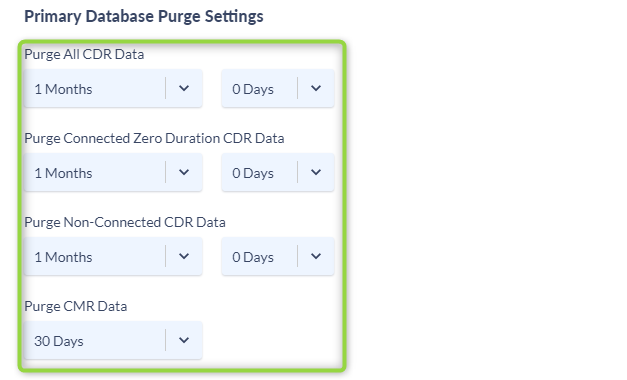
- Once you have completed all of the above steps click Save and Continue.
- Click Create Database.
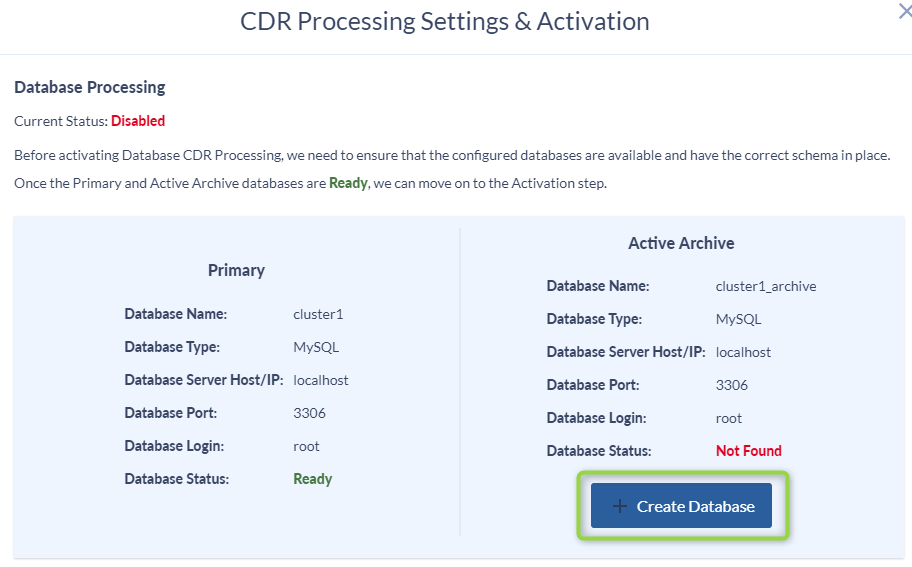
- Click Activate.
- Click Close.